在社保远程身份验证、反电信诈骗等公共服务领域,精准的声纹识别技术也将更好地降本增效、服务民生,不需要再“居住异地,千里奔波”,更避免“九旬老人社保年审,家人抬着爬上三楼”。
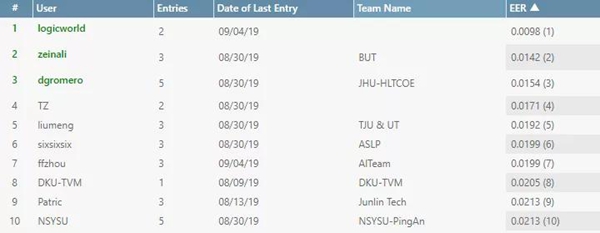
近日,在国际声纹识别权威竞赛VoxSRC上,依图算法夺得第一,等错误率降到0.0098、大幅领先第二名。
并且,依图团队(参赛队伍名为logicworld)在使用指定数据的情况下取得了优于其他团队使用不限数据得到的结果,表明依图声纹识别技术已达世界领先水平。
(竞赛的任务是判断两段音频是出自同一个人还是两个不同的人,算法的输出结果用等错误率(EqualErrorRate,EER)来衡量,EER越小系统性能越好)
0.0098的等错误率意味着什么?
首先,日常生活应用基本能够满足,笔记本电脑和汽车的声纹锁功能越来越可靠,智能硬件上的虚拟助理将不会被他人用同样的关键词唤醒,成为真正属于你的个人助理。
在社保远程身份验证、反电信诈骗等公共服务领域,精准的声纹识别技术也将更好地降本增效、服务民生,不需要再“居住异地,千里奔波”,更避免“九旬老人社保年审,家人抬着爬上三楼”。
声纹识别拥有广阔的应用前景。不仅如此,将语音识别与声纹识别、语义理解相结合,就能知道“是谁因为什么说了什么”,将大幅增强智能语音个性化服务,实现真正意义上的交互。
VoxSRC是由英国牛津大学、韩国互联网巨头Naver、斯坦福国际研究院和麻省理工学院联合发起的全球声纹识别竞赛,被誉为“声纹识别界的ImageNet竞赛”。
本次比赛采用的数据集基于开源数据集VoxCeleb,由牛津大学团队于2017年发布,后来逐渐扩充,现在是声纹识别领域规模最大、标注最完备的开源数据集之一。
VoxCeleb来自YouTube名人采访视频,包含了7000多个来自不同种族、口音、职业和年龄的说话人,超过100万段的说话声,2000多小时的音频和视频,且基本都含有背景噪音、笑声、说话声重叠及其他杂音,非常考验算法的实战水平。同时,本次比赛测试数据不含标注,无法用来训练或调整系统,确保了结果的公正与公平。
今年的VoxSRC吸引了来自海内外多支队伍参与,包括约翰霍普金斯大学、法国国家信息与自动化研究所、清华大学、中山大学等知名高校和研究机构,以及平安科技、NEC等大型企业。
成立7年来,依图在视觉感知、自然语言处理、语音识别、智能决策等多技术领域发展,这次参赛VoxSRC是依图在语音领域的一次新尝试。
未来,依图将在多算法领域持续投入,推进多模态技术融合、软硬件协同开发,将世界领先的人工智能算法与行业场景深度结合,推动人工智能应用落地。