“当前发展通用视觉的核心,是提升模型的通用泛化能力和学习过程中的数据效率。面向未来,‘书生’通用视觉技术将实现以一个模型完成成百上千种任务,体系化解决人工智能发展中数据、泛化、认知和安全等诸多瓶颈问题。”上海人工智能实验室主任助理乔宇表示。
11月17日,上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学,共同发布新一代通用视觉技术体系“书生”(INTERN),该体系旨在系统化解决当下人工智能视觉领域中存在的任务通用、场景泛化和数据效率等一系列瓶颈问题。
书生作为中国古代读书人的经典形象,代表着一个通过不断学习、不断成长进而拥有各方面才能的人格化角色:从基础的知识技能学习开始,到对多种专业知识触类旁通,进而成长为拥有通用知识的通才。将全新的通用视觉技术体系命名为“书生”,意在体现其如同书生一般的特质,可通过持续学习,举一反三,逐步实现通用视觉领域的融会贯通,最终实现灵活高效的模型部署。
书生(INTERN)技术体系可以让AI模型处理多样化的视觉任务
“当前发展通用视觉的核心,是提升模型的通用泛化能力和学习过程中的数据效率。面向未来,‘书生’通用视觉技术将实现以一个模型完成成百上千种任务,体系化解决人工智能发展中数据、泛化、认知和安全等诸多瓶颈问题。”上海人工智能实验室主任助理乔宇表示。
商汤科技研究院院长王晓刚表示,“‘书生’通用视觉技术体系是商汤在通用智能技术发展趋势下前瞻性布局的一次尝试,也是SenseCore商汤AI大装置背景下的一次新技术路径探索。‘书生’承载了让人工智能参与处理多种复杂任务、适用多种场景和模态、有效进行小数据和非监督学习并最终具备接近人的通用视觉智能的期盼。希望这套技术体系能够帮助业界更好地探索和应用通用视觉AI技术,促进AI规模化落地。”
目前,技术报告已在arXiv平台发布[1],基于“书生”的通用视觉开源平台OpenGVLab也将在明年年初正式开源,向学术界和产业界公开预训练模型及其使用范式、数据库和评测基准等。
OpenGVLab将与上海人工智能实验室此前发布的OpenMMLab[2]、OpenDILab[3]一道,共同构筑开源体系OpenXLab,助力通用人工智能的基础研究和生态构建。
▎一个基模型覆盖4大视觉任务,26个场景
随着人工智能赋能产业的不断深入,人工智能系统正在从完成单一任务向复杂的多任务协同演进,其覆盖的场景也越来越多样化。借助“书生”(INTERN)通用视觉技术体系,业界可凭借极低的下游数据采集成本,快速验证多个新场景,对于解锁实现人工智能长尾应用具有重要意义。
根据相关技术报告,一个“书生”基模型即可全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务。在ImageNet[4]等26个最具代表性的下游场景中,书生模型广泛展现了极强的通用性,显著提升了这些视觉场景中长尾小样本设定下的性能。
相较于当前最强开源模型(OpenAI 于2021年发布的CLIP[5]),“书生”在准确率和数据使用效率上均取得大幅提升。
书生(INTERN)在分类、目标检测、语义分割、深度估计四大任务26个数据集上,基于同样下游场景数据(10%),相较于最强开源模型CLIP-R50x16,平均错误率降低了40.2%,47.3%,34.8%,9.4%。同时,书生只需要10%的下游数据,平均错误率就能全面低于完整(100%)下游数据训练的CLIP。
具体而言,基于同样的下游场景数据,“书生”在分类、目标检测、语义分割及深度估计四大任务26个数据集上,平均错误率分别降低了40.2%、47.3%、34.8%和9.4%。
“书生”在数据效率方面的提升尤为令人瞩目:只需要1/10的下游数据,就能超过CLIP基于完整下游数据的准确度。例如,在花卉种类识别FLOWER[6]任务上,每一类只需两个训练样本,就能实现99.7%的准确率。
▎七大模块:打造全新技术路径
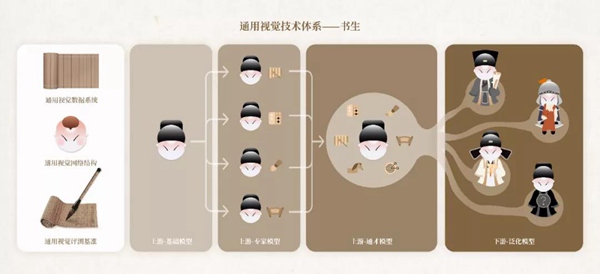
通用视觉技术体系“书生”(INTERN)由七大模块组成,包括通用视觉数据系统、通用视觉网络结构、通用视觉评测基准三个基础设施模块,以及区分上下游的四个训练阶段模块。
“书生”的推出能够让业界以更低的成本,获得拥有处理多种下游任务能力的AI模型,并以其强大的泛化能力支撑智慧城市、智慧医疗、自动驾驶等场景中大量小数据、零数据等样本缺失的细分和长尾场景需求。
通用视觉技术体系“书生”(INTERN)由七大模块组成,包括3个基础设施模块、4个训练阶段模块
在“书生”的四个训练阶段中,前三个阶段位于该技术链条的上游,在模型的表征通用性上发力;第四个阶段位于下游,可用于解决各种不同的下游任务。
第一阶段,着力于培养“基础能力”,即让其学到广泛的基础常识,为后续学习阶段打好基础。
第二阶段,培养“专家能力”,即多个专家模型各自学习某一领域的专业知识,让每一个专家模型高度掌握该领域技能,成为专家。
第三阶段,培养“通用能力”,随着多种能力的融会贯通,“书生”在各个技能领域都展现优异水平,并具备快速学会新技能的能力。
在循序渐进的前三个训练阶段模块,“书生”在阶梯式的学习过程中具备了高度的通用性。
当进化到第四阶段时,系统将具备“迁移能力”,此时“书生”学到的通用知识可以应用在某一个特定领域的不同任务中,如智慧城市、智慧医疗、自动驾驶等,实现广泛赋能。
▎产学研协同:开源共创通用AI生态
作为AI技术的下一个重大里程碑,通用人工智能技术将带来颠覆性创新,实现这一目标需要学术界和产业界的紧密协作。
上海人工智能实验室、商汤科技、香港中文大学以及上海交通大学,未来将依托通用视觉技术体系“书生”(INTERN),发挥产学研一体化优势,为学术研究提供平台支持,并全面赋能技术创新与产业应用。
明年年初,基于“书生”的通用视觉开源生态OpenGVLab将正式开源,向学术界和产业界公开预训练模型、使用范式和数据库等,而全新创建的通用视觉评测基准也将同步开放,推动统一标准上的公平和准确评测。
OpenGVLab将与上海人工智能实验室此前发布的OpenMMLab、OpenDILab一道,共同构筑开源体系OpenXLab,持续推进通用人工智能的技术突破和生态构建。