
提到计算机视觉领域的研究,大家可能最先想到的是人脸识别,其实还有一个更为实用的研究应用――行人再识别。行人再识别是利用计算机视觉技术在图像或视频中检索特定行人的任务,面临着视角变化大、行人关节运动复杂等诸多困难,是一个极富挑战的课题。本文就来为大家重点介绍一下行人再识别的一些基础知识及最新研究进展。
2017年,行人再识别研究飞速进展。例如,在公开数据集Market-1501上,一选正确率从2016年ECCV中较高的65.9%提高到2017年ICCV中的80+%,arXiv近期一些paper更是将该指标刷新到95%左右。来自清华大学信息认知与智能系统研究所的孙奕帆同学在ICCV 2017中一篇spotlight论文《SVDNet forPedestrian Retrieval》。这篇论文将全连接层权矩阵解读为特征空间中的一组投影基或是一组模板,联合奇异值分解(SVD)优化深度特征学习过程,取得了显著的性能提升,并揭示了非常有趣的机理现象。以下内容根据孙奕帆同学在雷锋网GAIR大讲堂上的直播分享整理而成。视频回放地址:http://www.mooc.ai/open/course/381
孙奕帆,清华大学电子系博士在读,主要研究方向为计算机视觉、行人再识别及深度学习应用。
分享主题 :行人再识别论文介绍及最新进展

分享内容
大家好,我是来自清华大学信息认知与智能系统研究所的孙奕帆。这次分享主要是以下三方面:
行人再识别任务简介;
SVDNet for Pedestrian Retrieval论文讲解;
行人再识别最近进展介绍及下一步热点预测(结合最新论文);
提到CV,大家首先想到的是人脸识别,其实行人再识别作为新兴研究方向在最近几年受到的关注程度是非常高的。为什么要进行行人再识别呢?
从学术研究来看,2008年以来,在三大顶会上收录的有关行人再识别的论文数量是逐年递增的。
从产业界来看,不管是老牌的计算机视觉公司如海康威视,还是新晋独角兽face++,商汤科技,还有一些像BAT,华为等科技巨头们对行人再识别都非常关注,他们在技术,算法,数据,人才上都有一定的积累。
从政策上来,行人再识别也受到一定的牵引。公安部推出平安城市概念,并且发布了较多的预研课题,相关行业标准也在紧锣密鼓制定当中。

2017年是行人再识别取得最大突破的一年。ICCV 2017中有16篇被接受的paper都是关于行人再识别。其中有两篇亮点paper,今天着重介绍其中一篇。
我先简单介绍一下行人再识别这个任务本身,希望从事计算机视觉的其他研究领域的人也能参与到行人再识别的研究当中。
行人再识别首先是计算机视觉任务,它的特点是给定一个感兴趣的人,行人再识别Re-ID需要在其他时间,其他地点,其他相机再次将人物指定出来。对于训练集,测试集来讲,它很大的一个特点是没有ID上的重叠。这和图像分类有很大不同,图像分类所有的类在训练阶段都是可以见到并且学习的。

人脸识别和行人再检测最大的区别是行人再识别是工作在非合作状态下,也就是说所采集的行人不需要配合你做一些动作。而人脸识别最早是工作在合作状态下,虽然现在随着技术的发展,人脸验证可以做到半合作状态,但是大部分情况下都不是完全非合作。由于行人图像相对难标注,获得的训练数据也是相对较少,以及一些别的原因,目前人脸识别的准确率要高一点。

行人再识别的应用领域
比如可以通过行人再识别做跨视角的嫌疑犯追踪。同样也可以和人脸识别联合起来获得一个在监视场景下的身份鉴定效果。在商业上,比如可以在实体零售里,判断同一个客户对商品的感兴趣度。

行人再识别的标准流程
首先给定一个初始视频之后,开始进行行人的检测,把检测到的所有行人形成一个候选库,叫做gallery。然后把gallery里面所有的图像提取特征,在给定一个需要查询的行人之后,叫做query,用同样的方法提取特征,并比较与侯选库里的特征之间的距离,最后返回检索结果。行人检测是相对一个独立的环节,通常关注于后面的特征对比。

论文中关于SVDnet的工作
首先我做了很多工作去试图理解CNN到底学到了什么?我用传统数据工具奇异值分解来优化深度学习的过程,这一点也是很有特色的。

关于这篇paper的动机。
行人再识别常用的深度学习方法通常有三个步骤。首先在训练集上训练一个分类网络,然后,在网络收敛之后,用它的全连接层的输出作为他的特征表达。最后,对所有的图像特征,计算他的欧氏距离,判断他们的相似性。
我们在这篇paper中提出了SVDNet,目标就是在这个特征表达层学到一个正交权矩阵。

SVDNet结构如图

它也是建立在通用图像分类的深度学习网络基础上的 ,和这些通用网络几乎没有什么差别,差别在于特征表达层会用一个具有正交权矩阵的Eigenlaye来代替传统的全连接。

用SVD去相关过程
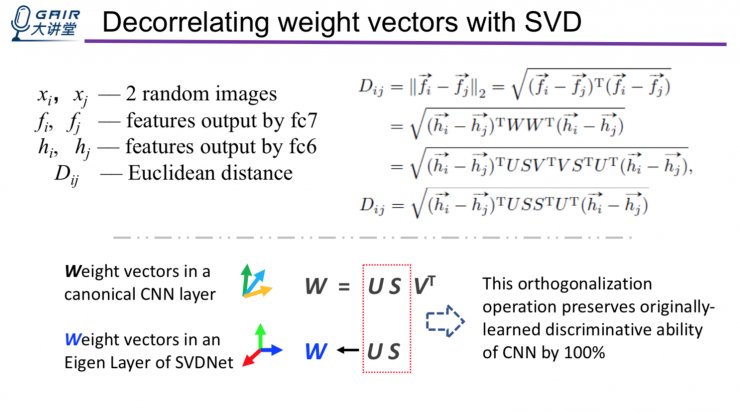
有了SVD去相关过程后,额外设计了一个训练步骤,叫做张弛迭代法。在紧张训练时,性能表现提升,在松弛训练阶段下性能不变,甚至略微降低。但总体的趋势是上升。

紧张训练阶段和松弛训练阶段特点

SVDNet的性能表现

我们这个工作现在已经把它扩展到图像分类任务上。
关于SVDNet,我也准备了比较细节的讨论,大家可以去的我github看源代码,在替换W的时候,不是简单的替换,而是有一个重新排序的过程,这其实是跟奇异值分解数值解法的一些特点是有关系的,我在github上有解释。
还有很多人问,如果用一个软的正则项能不能得到类似结果,这个实验我们也做了,性能提升比较小。不光是正交本身,如何获得正交效果对于SVDNet也是同样重要的。

另外我觉的比较有启发意义的是,SVD是对权矩阵进行正交化,它对特征表达本身进行去相关有什么联系也是值得思考的。这里就有两篇论文是这么做的,推荐大家看看。(论文题目在上图中)
arXiv 上的最新进展
arXiv上有一些最新研究是如何提高当前已经非常高(甚至可以说是超越了人类水准)的一个水平的,例如在market-1501上到一选准确率达到了90%~95%的区间。这里介绍三篇paper,他们有一些共同点,他们都使用了part model来提取部件级别的特征,但他们在如何产生part这个核心问题上所采用的策略又是完全不一样的。感兴趣的同学可以找来看一看。



未来的目标和挑战
当我们在强监督场景下的Re-ID已经取得这样高的水平之后,实际上Re-ID距离实际应用仍然有很多问题尚待解决。
我们都会发现实验模型在有的数据集上性能表现很好,但换到另一个难度更大数据集上,性能就会大幅下降。在面对真实复杂的外界环境,运用起来往往效果会更差。
另外就是当模型在一个数据集训练完之后,去另一个数据集测试,性能会出现非常明显的下降,这个下降是不允许的。在实际运用中,我们不可能对每一个相机采集到的数据都进行一定程度的标定,我希望在十多个相机的训练结果后可以泛化到很多没有标定数据的相机下,这样我们才能部署一个非常实用的系统。
最后提出两个开放性问题和大家一块思考:
SVDNet能够单独与metric loss (contrastive \triplet )联合使用吗?
行人再识别从人脸识别中学习到了很多经验和做法。行人再识别研究中的一些新做法是否可能应用于人脸识别?
以上就是我的所有分享。

微信扫描二维码,关注公众号。

