
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。当前,AI芯片主要分为 GPU 、FPGA 、ASIC 。
人工智能大势之下,芯片市场的蛋糕越做越大。有分析认为,到2020年AI芯片市场规模将达到146.16亿美元,约占全球人工智能市场规模12.18%。
本期的智能内参,我们推荐来自天风证券的AI芯片市场报告,结合智东西市场观察,从市场和流派出发盘点AI芯片的发展现状,分析四大蓝海的未来格局。
AI "脑力" 之源
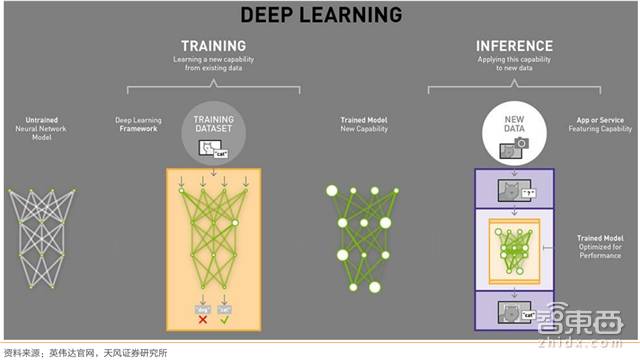
▲深度学习在神经网络模型的应用中主要分为上游训练端和下游推理端
互联网大数据的兴起对超算芯片提出了新的需求,人工智能(AI)亦如是。AI的“脑力”核心在于芯片和算法。
其中,AI算法的目前的主流方案是深度学习/强化学习,并已经被AlphaGo Master 和Zero成功验证可行性。深度学习即通过构建一种深层非线性网络结构,来实现复杂函数逼近及自动特征提取,具有强大的从少数样本集中挖掘数据统计规律的能力。

▲典型AI芯片商一览
另一方面,芯片,则为复杂的计算任务提供支撑(随着模型的逐渐复杂化,浮点运算的数量也呈指数级增长至 ExaFLOPS)。
2015 年微软ResNet 含有 6000 万个参数,运算量为 7 ExaFLOPS(百亿亿次浮点运算)。2016 年百度语音识别系统 Deep Speech 2 的参数量上升到 3 亿个,运算量提升至 20 ExaFLOPS。而今年Google 的 NMT 神经网络机器翻译系统,参数量达 87 亿个,需要 105 ExaFLOPS 的运算量。
因此,本质上,是摩尔定律的突破和并行计算以及云计算的发展,让人工智能开始得以普及。没有 GPU,人们就无法快速的处理海量数据,而数据训练的匮乏,会让深度学习的效率还不如人类工程算法(human engineering algorithm)。
GPU称雄 ASIC割据

▲四大芯片的 “通用性和功耗的平衡”

▲目前深度学习领域常用的四大芯片类型
2011年,吴恩达率先将GPU用于谷歌大脑,发现12颗GPU可提供约2000颗CPU的深度学习性能,之后纽约大学、多伦多大学及瑞士人工智能实验室纷纷在GPU上加速其深度神经网络。
可以说,在过去的几年,尤其是2015年以来,人工智能大爆发就是由于英伟达公司的GPU得到广泛应用,使得并行计算变得更快、更便宜、更有效。

▲GPU和CPU结构上的区别
GPU比CPU拥有更多的运算器(Arithmetic Logical Unit),只需要进行高速运算而不需要逻辑判断,其海量数据并行运算的能力与深度学习需求不谋而合。因此,在深度学习上游训练端(主要用在云计算数据中心里),GPU 是当仁不让的第一选择。目前GPU的市场格局以英伟达为主(超过70%),AMD 为辅,预计 3-5 年内 GPU 仍然是深度学习市场的第一选择。
下游推理端更接近终端应用,更关注响应时间而不是吞吐率,需求更加细分,除了主流的GPU芯片之外,还包括CPU、FPGA( Xilinx、英特尔Altera、Lattice 及 Microsemi等)、ASIC (英特尔Nervana Engine、Wave Computing 的数据流处理单元、英伟达的DLA、谷歌 TPU、寒武纪 NPU等)也会在这个领域发挥各自的优势特点。

▲FPGA:现场可编程门阵列
目前来看,下游推理端虽可容纳 CPU、FPGA、ASIC 等芯片,竞争态势中英伟达依然占大头,但随着AI的发展,FPGA的低延迟、低功耗、可编程性(适用于传感器数据预处理工作以及小型开发试错升级迭代阶段)和ASIC的特定优化和效能优势(适用于在确定性执行模型)将凸显出来。

▲赛灵思提供的 FPGA 与 CPU 性能对比优势
Grand View Research 分析,2015年全球FPGA总市场规模达 63.6 亿美元,预计到2024年FPGA市场规模将达到142亿美元。
其中,Xilinx 的市场份额为 49%,主要应用到工业和通讯领域,但近年亦致力于在云计算数据中心的服务器以及无人驾驶的应用;Altera(已被英特尔收购)的市场份额约为 40%,定位跟 Xilinx 类似;莱迪斯半导体(Lattice Semiconductor)的市场份额约为 6%,主要市场为消费电子产品和移动传输,以降低耗电量、缩小体积及缩减成本为主;Microsemi (Actel)的市场份额约为 4%,瞄准通信、国防与安全、航天与工业等市场。目前 Altera 的 FPGA 产品被用于微软 Azure 云服务中包括必应搜索、机器翻译等应用中。
各家芯片商打法上,除了力推自家芯片,还会在整个AI生态上进行布局:
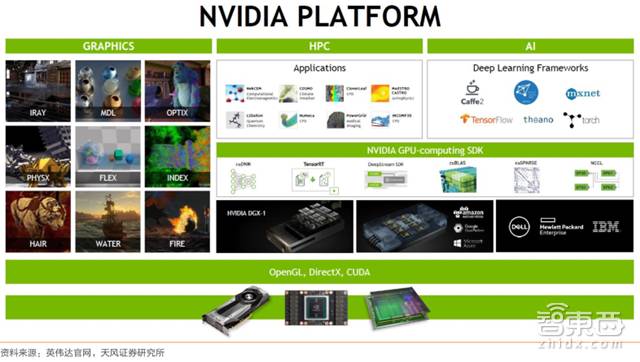
▲英伟达人工智能布局平台
英伟达拥有目前最为成熟的开发生态环境(CUDA 因统一而完整的开发套件,丰富的库以及对英伟达 GPU 的原生支持而成为开发主流,目前已开发至第 9 代,开发者人数超过 51万);

▲皮查伊在 2016 I/O 大会上介绍 TensorFlow
Google 的 TPU 也结合 TensorFlow 开源开发环境,并公布了 TensorFlow Research Cloud 云开发平台;

▲AMD GPU规划路进
AMD 通过CPU(EPYC)+GPU(Vega)+ROCm的开源生态,打造GPU计算最通用开源平台,并合作谷歌云进军云计算打开高端市场,合作THATIC(天津海光先进技术投资有限公司,是中科曙光的控股子公司)打开国内数据中心CPU服务器市场。
开源时代生态为天,硬件厂商以开源之态,本质上是抢夺业界事实标准的控制权,但随之而来的也是整个芯片行业设计门槛和研发成本的不断降低。
四大场景的芯片赛道
数据中心蓝海正当时

▲当前英伟达GPU在数据中心的使用情况
在数据中心抢滩战中,英伟达可谓拔得头筹:2016年公司数据中心业务带来8.3 亿美元收入,同比增长145%;今年的增长的动力落在了Volta架构V100(训练吞吐量提高至上代Pascal的12倍)的身上,前9个月收入已达 13.26 亿美元,同比增长148%。

▲英伟达基本垄断数据中心GPU
从市场占有率来看,目前全球云计算巨头基本使用英伟达GPU进行深度学习与算法加速,且相对于AMD,英伟达先发的构架升级以及广泛成熟的开发生态环境优势明显。不过,AMD或将接着合作百度、中科曙光的机会依靠GPU的捆绑销售,加速切入国内数据中心和AI发展快车道。

▲英特尔计划在数据中心里提供 FPGA 加速
值得注意的是,自2015年6月167亿美元收购FPGA芯片厂Altera后,英特尔也宣布计划在数据中心里提供 FPGA 加速;与此同时,TensorFlow团队公布了 TensorFlow Research Cloud 云开发平台,向研究人员提供一个具有 1000 个云TPU 的服务器集群,用来服务各种计算密集的研究项目,第二代TPU也可用于深度学习上游训练环节,并将部署在谷歌云计算引擎平台上,真正带入云端。

▲TPU Pod,由64台二代TPU 组成,算力达 11.5 petaflops
从市场容量/前景来看,云计算数据中心成为不可逆转的趋势,超级数据中心也越来越依赖GPU来更快地处理高要求的工作负载。目前,全球服务器中GPU的渗透率仅有 0.24%并基本被英伟达垄断,天风证券预计英伟达数据中心业务在2020年前将达40亿美元,对应全球服务器GPU 渗透率也将达 4 倍以上增长。
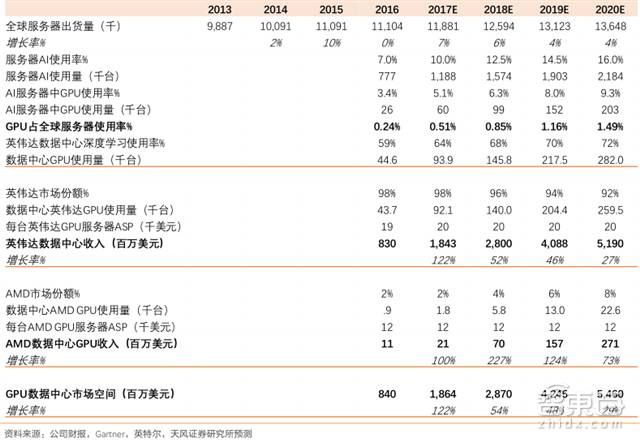
▲全球服务器 GPU 市场估计
自动驾驶开启黄金十年
全球自动驾驶 L1-L5 渗透率预测
天风证券认为,以 2020 年为界,全球将开启无人驾驶“黄金十年”。L3 半自动驾驶水平以上的行业发展,需要整个汽车行业供应商关系的重组和整合。包括:
“车企+ 供应商+ 芯片巨头+ 打车软件+ 物流公司”新格局
1、形成“车企+供应商+芯片巨头+打车软件+物流公司”的格局;
2、共享经济下的租车、打车以及商业货运物流领域会最快落地得到应用;
3、L4 相对比 L1、L2,单车系统零部件支出会增长 470%,从 545 美元升至 3100 美元/车。
L1 到 L4 单车零部件成本变化
英伟达指出,从 ADAS 提升到 L3 半自动驾驶所需的计算难度会提升 5 倍,而关键的L3向L4提升需要 50 倍,从 L4 提升到 L5 则需要 2 倍。因此,汽车电子化和智能化的方向将持续提高科技类公司在汽车产业链内的重要程度(三星收购哈曼,高通收购 NXP,英特尔收购Mobileye),营造了“车企+ 供应商+ 芯片巨头+ 打车软件+ 物流公司”的新格局。
目前,无人驾驶上游系统解决方案逐渐形成英伟达与英特尔-Mobileye 联盟两大竞争者。
英伟达在硬件层面算力和研发节奏上成为当仁不让的先行军:此前,公司的汽车业务主要集中在汽车显示屏和影音系统(Drive PX),今年1月的 CES 大会上发布无人驾驶的整体布局(从车载超级电脑平台以及人工智能驾驶系统, Xavier),10 月英伟达在德国慕尼黑的 GTC Europe 大会上,发布了面向完全自动驾驶 L5 级别的新一代 Drive PX 人工智能车载计算平台 Pegasus。英伟达智能汽车合作方有大众(优化城市交通)、奥迪(联合Mobileye、Delphi 等设计的全球首款搭载 L3 级自动驾驶的量产车,新一代A8)等。
英特尔给出的市场空间指引:汽车电子化和智能化整个市场空间,包括广告系统、数据和服务将从2020年的200亿美元提升到2030年的700亿美元。
EyeQ系列芯片参数介绍
英伟达的竞争对手,也就是被英特尔以每股 63.54 美元价格收购的 Mobileye。天风证券指出,Mobileye的机器视觉算法将与英特尔的芯片、数据中心、AI、传感器融合,以及地图服务等方面产生强大的协同合作效应,联手打造“软硬兼施”的全新无人驾驶供应商。目前,英特尔-Mobileye联盟拥有全行业最广泛的车企合作关系,且商业路径十分明晰:从 ADAS 出发,逐步完善功能模块,提高自动化程度,进化到EyeQ5(预计2020年推出,算力15万亿次)将会成为一个开源性、定制化、可升级的标准解决方案,打造成为无人驾驶界的Android。
除了上述两大主力汽车芯片竞争方,百度虽然与英伟达合作密切(Apollo开放平台从数据中心到自动驾驶都将使用英伟达技术,包括Tesla GPU和DRIVE PX 2,以及CUDA和TensorRT在内的英伟达软件),却也采用Xilinx的FPGA芯片加速机器学习,用于语音识别和汽车自动驾驶。
虚拟货币小蛋糕
GPU 矿机盈利估计
2017 年以来,数字虚拟货币连创新高,以太坊(Ethereum)技术下的以太币(ETH)涨逾30倍,比特币(BTC)也涨逾 7 倍突破 8000 美元。全球数字货币市值也从 180 亿美元增长至逾 2300亿美元。受益于数字货币的持续高度关注,通过显卡“挖矿”而获取货币的热潮,也发掘了对 AMD 和英伟达显卡的需求。
根据 cryptocompare 网站数据,AMD RX 470 GPU的矿机有明显优于英伟达 GTX 970 GPU 的经济回报,为了有效消弭挖矿和游戏需求冲突,并避免二手卡问题,英伟达针对虚拟数字货币挖矿热潮推出专门挖矿显卡(基于 GTX 1060 6GB 产品,完全取消显示输出接口,仅提供 90 天的质保);AMD 则发布了专门的挖矿驱动 Radeon Software Crimson ReLive Edition Beta for BlockchainCompute,为区块链计算工作负荷优化性能。
英伟达 CEO Jensen 在 Q3 季报会议上屡次被问及数字货币挖矿对公司业务的影响,他5次强调:挖矿市场对英伟达长期来说将会是“微小但不是零的”。数字货币挖矿对 GPU 巨头的影响整体空间有限,目前挖矿对显卡需求的驱动虽会持续存在但将进一步趋平。这主要是因为:
1、遵循比特币挖矿路径,挖矿需求会向专门芯片矿机转移;
2、以太币正在进行“工作量证明”向“权益证明”的升级,算力需求将会下降;
3、挖矿市场的狂热需求也会影响正常游戏显卡市场的需求并带来二手卡问题,也不是英伟达和 AMD 所想见。
终端AI的抬头
AI 芯片的计算场景可分为云端AI 和终端 AI。NVIDIA首席科学家William Dally将深度学习的计算场景分为三类,分别是数据中心的训练、数据中心的推断和嵌入式设备的推断。前两者可以总结为云端的应用,后者可以概括为终端的应用。
终端设备的模型推断方面,由于低功耗、便携等要求,FPGA和ASIC的机会优于GPU 。而提到终端智能,不得不谈苹果的A11神经引擎和华为的麒麟970 NPU。
苹果A11搭载神经处理引擎,采用双核设计,每秒运算次数最高可达 6000 亿次
2017年9月,苹果发布了iPhone X,搭载64位架构A11神经处理引擎。为实现基于深度学习的高准确性面部识别解锁方式(Face ID),并解决云接口(Cloud-Based API)带来的延时和隐私问题,以及庞大的训练数据和计算量与终端硬件限制的矛盾,iPhone X采用了“师生”培训、中间层、联合图、分割GPU工作项、匹配框架的神经引擎等方案解决(详细方案参见第206期智能内参)。
华为海思麒麟 970 架构搭载寒武纪IP的NPU
另一个吃螃蟹的企业就是咱们的华为――麒麟 970。麒麟 970 采用 10nm 制程,搭载 Cortex-A73(CPU)、Mali-G72(GPU)和麒麟 NPU(神经网络处理单元)。其中,麒麟 NPU 采用了寒武纪的IP(1A芯片),目的是解决端侧AI(On-Device AI)。
寒武纪产品研发发展
寒武纪作为背靠中科院计算所和中科曙光的 AI 芯片独家首公司,既具有开发实力,又能够与中科曙光进行产业链互补,先后获得中科院1000万元专项资金支持和1亿美元的A轮融资,目前估值已接近 10 亿美元。
寒武纪 DianNao 系列主要产品与性能
寒武纪自下而上的策略,从提供低功耗嵌入式终端的本地智能处理芯片解决方案入手,计划逐步向服务器云端的训练处理芯片去布局,有望构建强大的用户生态圈。目前寒武纪主要有三条产品线:
1、IP 授权:智能 IP 指令集可授权集成到手机、安防、可穿戴设备等终端芯片中,2016 年全年拿到 1 亿元订单;
2、在智能云服务器芯片领域:作为 PCIe 加速卡插在云服务器上,希望能布局进入人工智能训练和推理市场;
3、开发面向家用智能服务机器人、智能驾驶、智能安防等领域的应用芯片。
智东西认为,AI芯片,或者说AI加速器目前有三个明确的技术路径,更为通用的GPU(既能作为图形处理器引爆游戏业务,又能渗透数据中心横扫训练端)、更可编程的FPGA(适用于迭代升级,各类场景化应用前景超大),以及更专业的ASIC(叩开终端AI的大门)。
其中,英伟达、英特尔两大传统芯片巨头在三大路径,特别是通用芯片和半定制芯片都有布局,掌握强大的先发优势,在数据中心、汽车等重要蓝海布局扎实;AMD和Xilinx则各自找盟友,特别是中国盟友,求突围;ASIC方面,谷歌从TPU出发开源生态进行布局,且二代TPU展露了训练端芯片市场的野心,寒武纪则坐拥国内半导体、芯片、智能终端等行业之势,且ASIC定制化的特点有效规避了传统巨头的垄断局面,有着可靠健康的发展路线。

微信扫描二维码,关注公众号。

