相较于1.0版本,「梧桐」大模型2.0在数据、推训以及测试发布等多个重要维度上,对产品开发架构进行了深入全面的重塑与优化,能够在图像质量、算法精度、算法生产率、服务效率和用户体验等方面给产品带来显著提升,为解决更细分、更碎片化的场景业务需求降本提效。
2024年4月,宇视在合作伙伴大会上升级发布了「梧桐」大模型2.0,并确立了“装备大模型化”的商业化落地路线。发布120天后「梧桐」大模型商业落地表现如何?今天就带大家一探究竟!
图 宇视合作伙伴大会上「梧桐」大模型2.0发布
相较于1.0版本,「梧桐」大模型2.0在数据、推训以及测试发布等多个重要维度上,对产品开发架构进行了深入全面的重塑与优化,能够在图像质量、算法精度、算法生产率、服务效率和用户体验等方面给产品带来显著提升,为解决更细分、更碎片化的场景业务需求降本提效。
数据融合分析,解决黑夜成像难题
最近惊艳行业的猎光2.0图像处理引擎,正是得益于「梧桐」大模型的AI算法加持,从而使前端
摄像机可以应对多种极黑/无光/微光场景挑战。
该算法具备超强的多场景数据融合分析能力,能够对不同场景下的数据进行精准而深入的融合与分析,从而实现对周围环境全方位的态势感知。即使在低至令人难以置信的≤0.0001 Lux的照度环境下,依然能够让图像呈现出如同在白昼中一般的鲜艳色彩。
图 传统全彩相机和猎光2.0相机效果对比
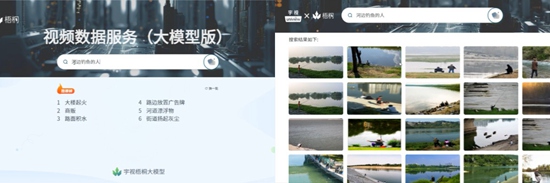
多模态能力融合,高效视频数据服务
「梧桐」大模型将自然语言处理能力、视频特征提取能力和语音内容理解能力进行深度融合,可以对用户输入的语言文字进行深度解析和语义理解,对用户输入的语音进行解码识别和分析, 同时通过大模型特征表示提取视频中的目标、地点、事件等多维信息,准确理解视频或图片内容,从而快速检索匹配出关键字或语音对应的视图内容。
例如,当需要搜索“河边钓鱼的人”的视频内容时,用户只需要输入文字描述,视频数据服务系统就能从海量的视频内容中快速检索出贴近用户意图的搜索结果,在城市管理、交通治理、园区运营等场景帮助提升管理效率和降低人工成本。
图 视频内容快速检索演示
深度学习训练,构建智能客服助手
「梧桐」大模型具备强大的深度学习能力,通过学习宇视多年积累的资料库,构建智能客服小助手,相较于传统的触发式客服机器人,不但对话更自然,且对用户的问题理解力更强,能够准确地回答更多问题,大幅降低人工客服成本。
图 宇视智能客服助手问答演示
场景算法快速生产,提升用户体验
基于「梧桐」大模型,可以快速完成场景算法模型的训练生产,如宇视面向文旅场景提供的旅拍兔VLOG服务,其中核心算法能力就是「梧桐」大模型提供的:可以快速将游客人像信息和视频画面自动匹配,生成最优视频片段,同时通过AI体态分析精准识别人体躯干、四肢到手指的精细动作以及面部的精细表情,精准捕捉游客的精彩POSE瞬间。最后基于多模态技术对各场景和动作进行分析,自动叠加最匹配的图层、特效,还能进行画面人物消除和画面优化。
图 游客照经过算法处理后的效果对比
大模型技术是AIoT行业当下最大的技术变量,宇视将持续探索「梧桐」大模型能力的高效应用,将更多创新成果惠及千行百业,守护安全美好生活!