当人类看一个场景时,他们看到的是物体和它们之间的关系。在桌子上面,可能有一台笔记本电脑,人坐在手机的左边,而手机在电脑
显示器的前面。许多深度学习模型在以这种方式看世界时很吃力,因为它们不了解单个物体之间的纠缠关系。如果不了解这些关系,一个旨在帮助厨房里的帮厨机器人将很难遵循“拿起炉子左边的铲子,把它放在砧板上”这样的命令。
为了解决这个问题,麻省理工学院的研究人员开发了一个模型,可以理解场景中物体之间的基本关系。他们的模型每次都代表单个关系,然后结合这些代表来描述整个场景。这使得该模型能够从文本描述中生成更准确的图像,即使场景中包括几个以不同关系排列的物体。
这项工作可以应用于工业机器人必须执行复杂的、多步骤的操纵任务的情况,如在仓库中堆放物品或组装电器。它还使该领域向着使机器能够像人类一样从环境中学习并与环境互动的方向迈进了一步。
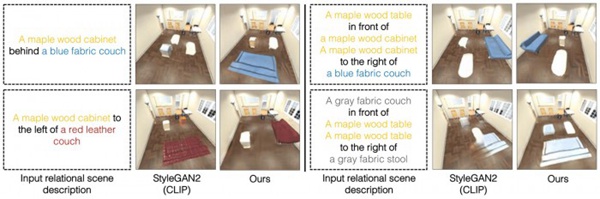
研究人员开发的框架可以根据对物体及其关系的文字描述生成一个场景的图像,在这个图中,研究人员的最终图像在右边,并正确地遵循了文字描述。
“当我看着一张桌子时,我不能说在XYZ位置有一个物体。我们的头脑不是这样工作的。在我们的头脑中,当我们理解一个场景时,我们真正理解它是基于物体之间的关系。我们认为,通过建立一个能够理解物体之间关系的系统,我们可以利用该系统更有效地操纵和改变我们的环境,”计算机科学和人工智能实验室(CSAIL)的博士生、该论文的共同主要作者杜一伦(音译)说。
杜一伦与共同第一作者、CSAIL博士生李爽(音译)和伊利诺伊大学香槟分校研究生刘楠(音译),以及脑与认知科学系认知科学与计算专业保罗-E-牛顿职业发展教授、CSAIL成员Joshua B. Tenenbaum,以及资深作者、电气工程与计算机科学专业德尔塔电子教授、CSAIL成员Antonio Torralba共同撰写了该论文。这项研究将在12月举行的神经信息处理系统会议上发表。
他们的系统会将这些句子分解成两个较小的片段,描述每个单独的关系(“一张木桌在蓝色凳子的左边”和“一张红色沙发在蓝色凳子的右边”),然后对每个部分单独建模。然后通过一个优化过程将这些部分结合起来,生成一个场景的图像。
研究人员使用了一种叫做基于能量的模型的机器学习技术来表示场景描述中的各个物体关系。这种技术使他们能够使用一个基于能量的模型对每个关系描述进行编码,然后以一种推断所有物体和关系的方式将它们组合起来。
李解释说,通过将每个关系的句子分解成更短的片段,系统可以以各种方式重新组合它们,因此它能够更好地适应它以前没有见过的场景描述。
“其他系统会从整体上考虑所有的关系,并从描述中一次性生成图像。然而,当我们有分布之外的描述时,比如有更多关系的描述时,这样的方法就会失败,因为这些模型不能真正适应一次就能生成包含更多关系的图像。然而,由于我们将这些单独的、较小的模型组合在一起,我们可以对更多的关系进行建模,并适应新颖的组合,”杜说。
该系统还可以反向工作--给定一张图像,它可以找到与场景中物体之间关系相匹配的文本描述。此外,他们的模型可以用来编辑图像,重新安排场景中的物体,使它们与新的描述相匹配。
理解复杂场景
研究人员将他们的模型与其他深度学习方法进行了比较,这些方法得到了文本描述,并负责生成显示相应物体及其关系的图像。在每一种情况下,他们的模型都优于基线。
他们还要求人类评估所生成的图像是否与原始场景描述相符。在最复杂的例子中,描述包含三种关系,91%的参与者认为新模型的表现更好。
“我们发现的一个有趣的事情是,对于我们的模型,我们可以把句子从有一个关系描述增加到有两个,或三个,甚至四个描述,而且我们的方法继续能够生成被这些描述正确描述的图像,而其他方法则失败了,”杜说。
研究人员还向模型展示了它以前没有见过的场景图像,以及每张图像的几种不同的文字描述,它能够成功地识别出最符合图像中物体关系的描述。
当研究人员给系统提供两个描述同一图像但方式不同的关系型场景描述时,该模型能够理解这些描述是等同的。
研究人员对他们的模型的鲁棒性印象深刻,特别是在处理它以前没有遇到过的描述时。
“这是非常有希望的,因为这更接近于人类的工作方式。人类可能只看到几个例子,但我们可以从这几个例子中提取有用的信息,并把它们结合起来,创造出无限的组合。而我们的模型有这样一个特性,使它能够从较少的数据中学习,但却能概括到更复杂的场景或图像代。”李说。
虽然这些早期结果令人鼓舞,但研究人员希望看到他们的模型在真实世界的图像上表现如何,这些图像更加复杂,有嘈杂的背景和相互遮挡的物体。
他们还有兴趣最终将他们的模型纳入机器人系统,使机器人能够从视频中推断出物体关系,然后应用这些知识来操纵世界上的物体。
捷克技术大学捷克信息学、机器人学和控制论研究所的杰出研究员Josef Sivic说:“开发能够处理我们周围世界的组成性质的视觉表征是计算机视觉中的一个关键性的开放问题。这篇论文在这个问题上取得了重大进展,它提出了一个基于能量的模型,明确地对图像中描绘的物体之间的多种关系进行建模。这些结果确实令人印象深刻,他没有参与这项研究。”