
多年以来,如何从单一图像估计人体的姿势和形状是多项应用都在研究的问题。研究者提出不同的方法,试图部分或者联合地解决此问题。本文将介绍一种端到端的方法,使用 CNN 直接从单个彩色图像重建完整的 3D 人体几何。
该领域的早期研究使用迭代优化方法从 2D 图像估计人体姿势和形状信息,一般通过不断优化估计的 3D 人体模型来拟合一些 2D 的观测结果,比如 2D 关键点 [4] 或者轮廓 [11]。
随着深度学习的崛起,很多研究试图用 CNN 以端到端的方式解决该问题,其中有些已经达到了更好的性能和更快的运行速度。但是,用 CNN 直接预测完整的人体网格并不简单,因为训练这样的模型需要大量的 3D 标注数据。
近期研究大都结合了某些参数化的人体模型,如 SMPL [13],转而去预测这些模型的参数 [9]。[22,27] 借由关节或分割输出的帮助改善性能。这种基于模型的 3D 表示形式将 3D 人体形状限制在低维线性空间里,使其更容易通过 CNN 模型学习,但由于线性模型的限制,其性能可能无法达到最优。
[39] 提议使用一种体积表示(volumetric representation)来估计人体形状,展现了一定的优点,在此过程中预测的 3D 关节位置被作为中间结果输出。
虽然 3D 表示有多种选择,但近期基于 CNN 的方法大都依赖于某些中间 2D 表示和损失函数来引导训练过程。
在这些方法中,单个 RGB 图像到 3D 人体网格的映射问题被分解为两步:首先得到某些类型的 2D 表示,比如关节热图、掩码或 2D 分割;然后基于这些中间结果预测 3D 表示 [16,5]。这些研究所选择的中间表示以及解决这些子任务的神经网络的输出质量,很大程度上会影响它们的最终效果。
云从科技的这项研究提出了一种高效的方法,从单个 RGB 图像中直接得到完整的 3D 人体网格。
这个方法和其他研究的主要区别有以下两个方面:首先,该研究提出的网络没有结合任何参数化的人体模型,因此该网络的输出不会受到任何低维空间的限制;其次,该方法的预测过程是一步到位的,没有依赖于中间任务和结果来预测 3D 人体。该研究在多个 3D 人体数据集上评估了这一方法,并将其与之前研究中的方法做了对比。
评估结果表明该方法的性能远超其他结果,且运行速度更快。
该研究的主要贡献如下:
提出了一个端到端的方法,从单个彩色图像直接得到 3D 人体网格。为此,研究者开发了一种新型 3D 人体网格表示。它能够把 2D 图像中的完整人体编码为姿势和形状信息,无需依赖任何参数化的人体模型。
把 3D 人体估计的复杂度从两步降到了一步。该研究训练了一个编码器-解码器网络,可直接把输入 RGB 图像映射到 3D 表示,无需解决任何中间任务,如分割或 2D 姿态估计。
进行了多次实验来评估以上方法的效果,并与现有的最优方法进行对比。结果显示,该方法在多个 3D 数据集上实现了显著的性能提升,运行速度也更快。

图 1:示例结果。
论文:DenseBody: Directly Regressing Dense 3D Human Pose and Shape From a Single Color Image

论文地址:https://arxiv.org/pdf/1903.10153.pdf
摘要:由于人体的高度复杂性和灵活性,以及 3D 标注数据相对较少,从 2D 图像得到 3D 人体姿势和形状可谓是一个难题。之前的方法大体上依赖于预测中间结果,比如人体分割、2D/3D 关节、以及轮廓掩码,将当前问题分解成多个子任务,从而利用更多 2D 标签或者结合低维线性空间内的参数化人体模型来简化问题。
在本文中,我们提出使用卷积神经网络(CNN),直接从单个彩色图像得到 3D 人体网格。我们设计了一种高效的 3D 人体姿势和形状表示,可以通过编码器-解码器结构的神经网络学习获得。实验表明我们的模型在多个 3D 人体数据集上达到了当前最优性能,同时运行速度更快。数据集包括 Human3.6m、SURREAL 和 UP-3D。
3. 本文提出的方法
3.1 3D 人体表示
之前的研究通常使用 SCAPE 和 SMPL 这样的可变形模型和体素来表示 3D 人体几何结构。本文提出的方法则用 UV 位置映射图来表示 3D 人体几何结构,其有如下优点:首先,它能保存点和点之间的空间邻接信息,相比一维的向量表示,该信息对精确重建更为关键;其次,相比体素这样的 3D 表示,它的维数更低,因为体素表示法中,大量不在表面上的点其实用处不大;最后,这是一个 2D 表示,所以我们能直接使用现成的 CNN 网络,例如 Res-net 和 VGG,使用计算机视觉领域的最新进展。
在人体重建领域,UV 映射图作为一种物体表面的图片表达方式,经常被用来渲染纹理图。在这篇论文里,我们尝试使用 UV 映射图来报答人体表面的几何特征。大多数的 3D 人体数据集提供的三维标注是基于 SMPL 模型的,SMPL 模型本身提供了一个自带的 UV 映射图,把人体切分成了 10 个区域。
DensePose 里面提供了另一种人体切分的方式,并提供了一个 UV 映射图,将人体切分成了 24 个区域。我们实验了两种切分方式,SMPL 的 UV 映射图获得了更好的实验结果。因此,在我们的方法中,我们采用这个 UV 映射图来存储整个人体表面的三维位置信息。
图 2 展示了不同分辨率下 UV 位置映射图的顶点变形和重采样时引入的误差。考虑到当前最优方法的全身精度误差(surface error)和关节精度误差(joint error)在几十毫米的数量级,我们选择了 256 的分辨率,它引入的 1 毫米全身精度误差可以忽略不计。另外,256 分辨率的 UV 映射图能够表示六万多个顶点,远多于 SMPL 的顶点数。

图 2:在不同的 UV 位置映射图分辨率下,由于变形和重采样引入的全身精度误差和关节精度误差,单位为毫米。
3.2 网络和损失函数
我们的网络采用编码器-解码器结构,输入是 256*256 的彩图,输出是 256*256 的 UV 位置映射图,其中编码器部分使用 ResNet-18,解码器是由四层上采样和卷积层组成。
不同于以前的方法中需要仔细设计和融合多种不同损失函数的做法,我们直接针对预测的 UV 位置映射图进行监督和设计损失函数 (见表 2)。为了平衡不同的身体区域对训练的影响,我们采用了权重掩模图来调整损失函数。此外,关节点附近的点的权重也进行了加重。

表 1:不同方法中采用的损失函数。

图 3:不同方法的框架与 DenseBody 对比。
3.3 实现细节
所有的图像都先做了对齐,使人位于正中。然后通过裁剪和缩放调整到 256x256,使得紧凑的边界框和图像边缘之间距离适中。图像经过了随机的平移、旋转、翻转和色彩抖动。我们要注意,数据增强的操作大都不简单,因为对应的真值数据也要进行相应的形变。
而当随机形变后的人体超过了 256x256 的画布,则该增强操作无效。我们用正交投影来得到位置映射图的 x-y 坐标,以避免深度信息的误差传播。真值数据的深度信息要经过适当缩放,以控制在 sigmoid 输出的值域里。
我们使用 Adam 优化器,学习率为 1e-4,mini-batch 的大小为 64,训练直到收敛为止(大概 20 个 epoch)。在单个 GTX 1080Ti GPU 上训练大约 20 个小时。代码实现基于 Pytorch。
4. 实验
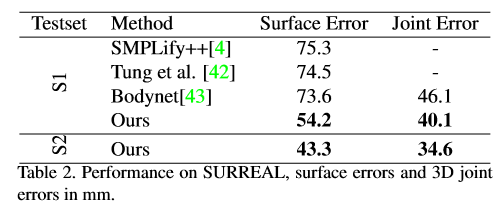
表 2:在 SURREAL 上的实验结果,全身精度误差和关节精度误差以毫米为单位。

表 4:UP-3D 上的实验结果。全身精度误差和关节精度误差以毫米为单位。

表 5:在单个 GTX1080TI 上的前向运行时,以毫秒为单位。1 表示在 TITAN X GPU 上运行。
本文为机器之心报道,转载请联系本公众号获得授权。

微信扫描二维码,关注公众号。

