
本文为AML实验室负责人Joaquin Candela在@Scale大会上发表了的关于如何将AI技术应用于Facebook各个领域的下半部分演讲内容。此篇中,Joaquin Candela和大家讲解了AI技术在视频理解平台、文本理解、语音识别、视频风格变换多个领域的应用,并配以实际案例帮助大家理解。上篇内容及演讲视频请看雷锋网(公众号:雷锋网)报道《Facebook AML实验室负责人:将AI技术落地的N种方法(上)》。以下为雷锋网编译。
图像视频理解:Lumos平台
Lumos的故事很有意思,它最初诞生于FAIR实验室,最初只是一个实验性的项目,当时有人提出,我们要不建一个可以理解所有Facebook上面图片的系统?这个项目开始的时候,看起来似乎不可能完成。后来这个项目的成员转来了AML,成了如今CV团队里的种子成员,接着我们跟FAIR实验室一起合作开发了新的Lumos平台。

在应用方面,Lumos如今每天都要对Facebook上的每张图片进行分析,处理的数量高达数十亿。要处理很多任务,比如:
为盲人描述图片
重现重要回忆
提供更好地图片和视频搜索结果
保护人们不受有害内容的侵扰
一件很酷的事情就是,我们有一个共享的训练库,Lumos上已经有超过一亿训练样本,并且这一数据还在增长。
去年,我们升级了Lumos的核心模型,不出意料,是的,更新成为了一个Deep Residual Network(Deep ResNet)。当我们启动新模型时,那感觉就像是,潮水升起,带着船只也升高。也就是说,Facebook公司内所有依赖Lumos的模型,一下子准确度都提高了。 但是,有一个问题,从无到有训练这些模型,然后转移到新的架构里,是需要重新训练的,而这会花费很长时间。还有就是,有很多的任务需要这样的模型,如果我们用专用的ResNet为每一个应用工作,当你整个公司有数百个应用的时候,你很快就会无法忍耐计算量和数据集的局限。
现在这两个问题,我们都一次解决了。我们解决问题的方式,比较像是一个多层蛋糕。
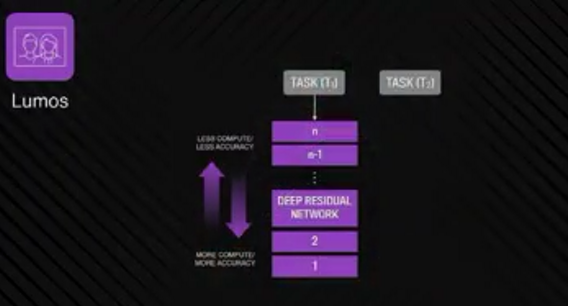
现在,你有一个大型主模型(master model),这个模型是用你所有的数据来训练的,并且解决了数千个不同的预测任务。这个模型定期更新,随着你处理越来越多的任务,那么之后,当你处理一个新任务时,并不需要从头开始做。ResNet已经学习的特征是非常有用的,所以你的出发点可以换到更高一层,而不是从原始的像素开始。
但是,这当中有一个需要寻找“平衡点”(trade off)的过程,如果你在靠近输出层(output layer)的地方开始,那么就不需要重复训练每一层的模型,这样的结果是,你很快就可以得到的一个新任务模型,但是就会牺牲一些准确性。相反的,如果你不采用这种方法,而是在靠近输入层(input layer)的地方开始,输入层特征更加通用,但是你要接下来训练很多层模型,这会花费你很多的精力。
所以要知道最好的“平衡点”是什么。所以,我来跟大家展示,一个新的任务团队来使用Lumos的时候,会是一个怎样的体验,记住,“易用性”是里面最关键的地方。
比如,我们要建立一个全新的模型,来分辨出“人骑马”的图片。那么最一开始,我们需要什么呢,当然是训练数据。然后用一些关键词,比如“人”、“马”等,从Facebook和Instagram的公开照片里,检索出关键词的图片。
当我们得到这些图片时,一个很酷的事情就是Lumos平台会做一些类别排序,你能够快速检索到特定类别的图片,你可以为你所有的数据打上符合或不符合的标签,制作成训练集 。然后你可以做一个我们称为“现场预览”(live preview),来看看它的运行状况如何,纠正一些错误。你所训练过的模型,Facebook的其他工程师在FBLearner Flow也可以重复利用。随着其他人对它的训练越来越多,这个模型也会变得越来越精确。
下面我跟大家展示另一个训练模型例子,你可以看到它被训练的效果很好。只要有了生产数据,这个模型就能在你的产品上运行起来。这意味着什么呢?这意味着只需要几分钟,我们就获得了一个新的模型,这个模型就有能力识别Facebook上发布的所有新照片。而我们每个人都可以在Facebook上用这个模型。就这么简单。
看它的一个成果,这是我女儿,她正在骑马。有趣的是,你可以在分类上看到“people riding on horse”,这说明Lumos起作用了。它识别出了horse,animal和people riding on horse。除此之外,它还有ranch(大牧场)标签,这说明之前有人让模型学习过“ranch”这个标签对应的是什么图形,同样道理,下面还有outdoor,nature和has person。
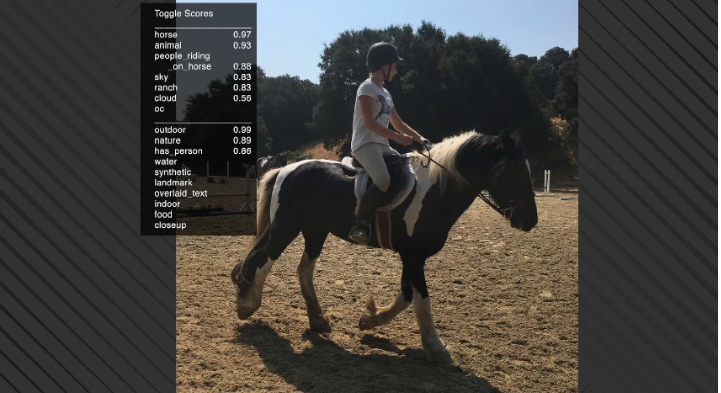
现在我知道它已经学会识别某些图片了,但这还不够。我还想知道它哪里有缺陷。
然后我就想,这里有没有“sitting on chair”的模型。接下来我看到了Lumos呈现出来的这张人坐在椅子上的图片。在这张图片的分类里有people sitting,face, table,indoor,restaurant indoor等几个标签,这都很好。但并没有chair这个标签,这很不可思议。不过不用担心,我已经知道怎么修补这个缺陷了。只需要训练这个模型几分钟,它就学会要在有chair的图片里加上“chair”这个标签了。

下面我给大家展示两个其他研发团队是如何应用Lumos平台的。
图片搜索。
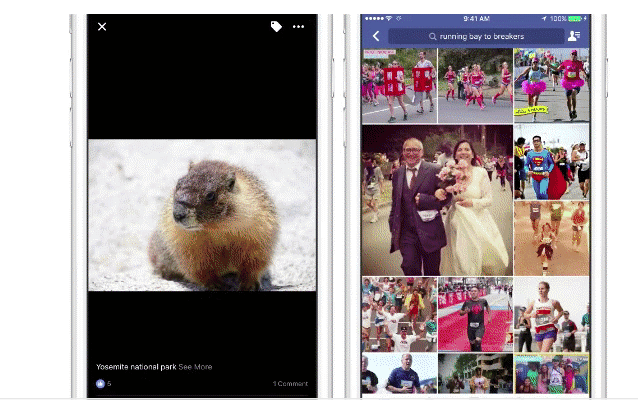
现在,纯粹的以图搜图技术已经投入应用了。大家中场休息的时候可以用自己的手机试一下,点击搜索引擎上的photo指令,用图片搜索图片。
我记得有一次我过生日的时候,我们没点生日蛋糕,而是由我自己亲手做了派拉(Paila,一种拉美菜)。我把和派拉的合照发布在了网上,但是上面并没有出现任何关于这道菜的描述,但是当我再次搜索派拉图片的时候,我看到了下面结果:
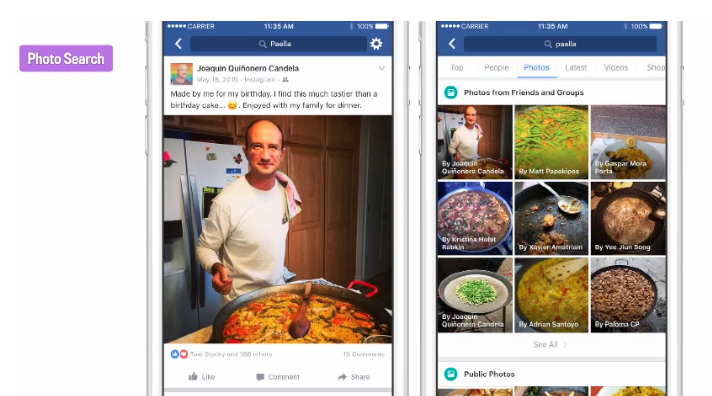
看,我的照片在搜索结果中,Lumos再次成功运行。这个过程很简单并且效果还可以,不过我们要求的是精益求精。
所以图片搜索的原理是什么呢?简单来说,搜索图片原理的关键之处就在于“概念”,即你搜索的内容和图片显示内容之间有共同的概念。搜索图片就是让Lumos对图片的预测和对搜索内容的预测匹配起来。
下面这张图片,看起来像是中央公园(central park)。
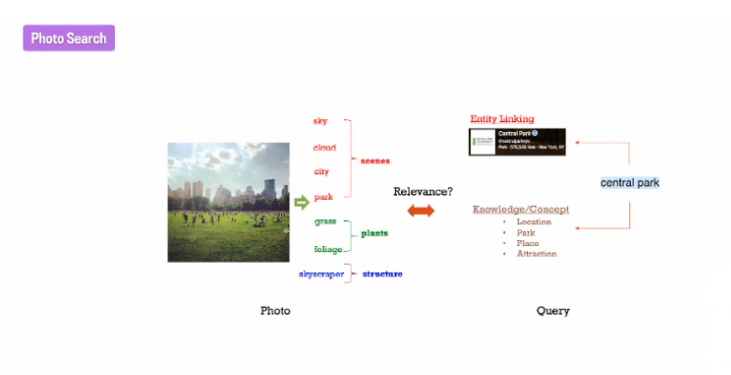
从图片中可以提取出的概念有sky,cloud,city,park,grass,foliage和skyscraper等。
而在查询(query)部分,我们用理解引擎把实体central park和要查询文本“central park”联系起来。 因此,查询机制从“central park”中提取出来的概念有location,park,place,attraction等等。现在,你有了两组概念,接下来的事情就是寻找其中的关联度 。而你所做的,就是输入查询“central park”,最后得的到底是不是你想要的图片,它们的概念匹配到底对不对。是的,它再一次成功运行了。
而接下来,我们为什么不能用这种方法做更多事呢?
我们希望用这种方法解决更多问题,因为它有很强的交互性(interactive)。我们上面说的认为挑选出来以训练分类器的概念,其实事实上照片不知道它对应的是哪一部分。所以更好的办法就是直接把图像和查询内容共同嵌入在共同潜在空间(common latent spaces)中,用减少排序损失(ranking loss)的方法进一步提高图片搜索的精确度。
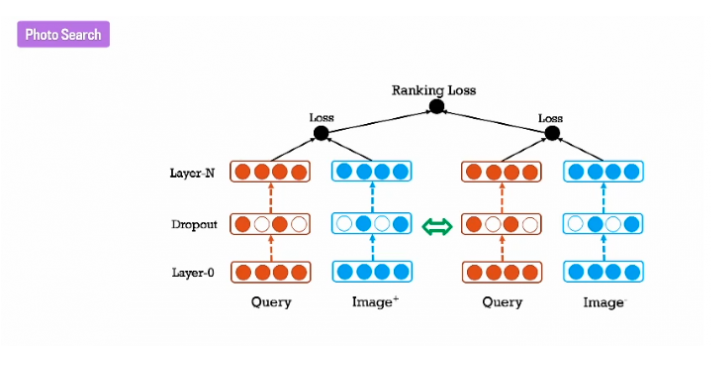
你的团队可以用这种方法训练分类器,看它的匹配性能强不强。在这个图中你看到query出现了两次,这表示这个研究团队在选择更合适的排序损失。他们会给同一个查询内容,然后看哪个带有标签的知识更匹配你要查的内容,以确保你的嵌入的排序损失达到最小化。而结果表明,用这种方法进行图片搜索,匹配度的确高了很多。
自动转换文本
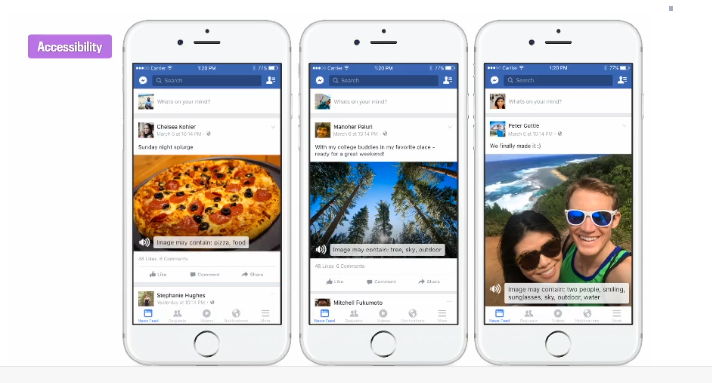
去年4月,我们公司上线了自动转换文本(automatic alternative text,AAT)技术。用该技术,Facebook可以通过图像识别认出用户发布的图片中包含的信息并读出来,帮助盲人“看到”网站上的图片 。我们周围的盲人有好几亿,所以解决帮盲人阅读网络上的图片这个问题迫在眉睫。

Facebook从这三张图中看到得分别是:左图――披萨、食物,中图――树、天空、户外、右图――两个人、微笑、太阳镜、户外、水。
而右图除了有实物“两个人”,还包含有人的动作“微笑”。我们发现Facebook可以读出这里面有人,可以读出来人在做什么。而对该技术的研发团队来说,他们想做的就是希望告诉盲人“图片中的对象在做什么”,这和仅告诉他们“图片里面有什么”,有相当大的区别。
大家可以看下面一个例子:

Facebook用语音描述了一张图片,“说”:Image may contain one person ,on stage and playing music al instrument(该图片可能包含了一个在舞台上弹乐器的人)。
而它聪明的地方在于,它并没有给出像one person,person on stage,person are playing musical instrument这样的描述。所以这是Facebook在进行自然语言处理(NLP)时,为了呈现出描述更符合自然语言所涉及到的另一个技术点。
进行图片搜索时我们同时用到了两项技术,一个是平台上的文本理解技术,另一个是计算机视觉技术,即Lumos。
深度语义识别产品: Deep Text
而我们接下来讲的是基于文本理解技术的另一个产品Deep Text。
就像做计算机视觉技术一样,Deep Text所需要处理的数据量之大和大数据对系统的要求之高,是难以想象的。每天在Facebook上发布的翻译帖子高达40亿条。语言对文字内容的依赖程度非常强,因此想要精确地分析短语语义,尤其是用一种语言来解释在另一种语言中原本不存在的现成说法。在这里我跟大家讲一个关于语言翻译的笑话,来说明语言真的非常难以理解。笑话是这样的,说有一个人要进行中俄互译,英译俄的英语原句本来是是“Out of sight,out of mind(看不见了,也就忘了)”,而再把译成的俄语反译为英语的时候,句子则变成了“invisible idiot(看不见的傻子)”
Deep Text的一些应用
用于销售
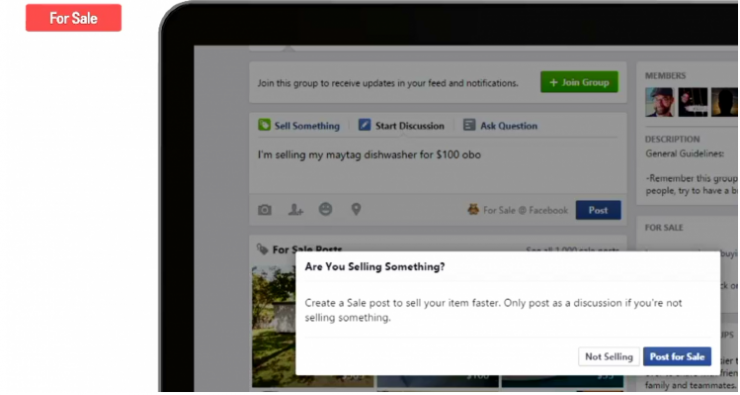
人们使用Facebook的范围,已经大大超出我们的想像,比如用它买卖产品,如下图所示。
你希望人们能用母语在上面发布信息,你需要发现他发布的信息中蕴含有销售意向,并且把帖子归类为销售帖,让你能更快完成交易。
用于移动聊天工具
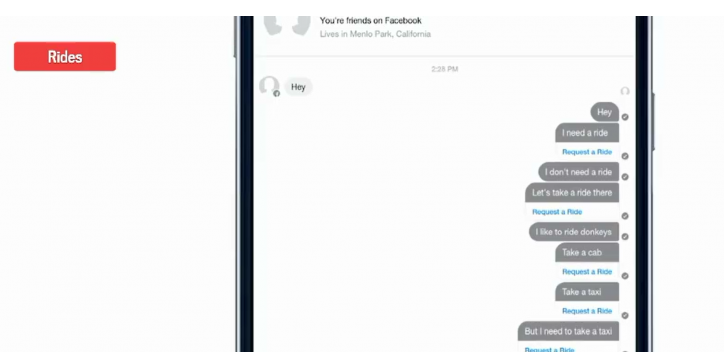
Deep Text另一个核心应用是在移动聊天工具上。比如你和一个朋友说“hey,我想搭个便车”, Deep Text就能识别出“需要坐车”,或者你发“我不需要搭便车”,那么它就不会出现任何提示,但你发“让我们打车去那吧”,“我喜欢骑驴”,“打个的士”,“打个出租车”, “但是我需要打个的”,它都会出现“需要坐车”的提示。
用于社交推荐
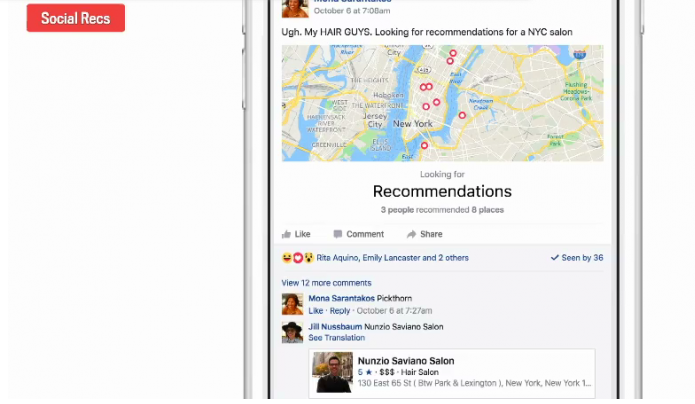
还有一个是用在社交推荐上。如果有人在上面发帖子,请朋友推荐个餐厅、美容院之类的,Deep Text就能自动把朋友们的选择推荐给你,并在地图上标出实体所处的地理位置。

语音识别

我们平均每天转录约100万个视频文件,为其自动加字幕 。这个功能对网站来说大有益处。很多地方性团体或企业都有网站,而用了我们这个功能之后,他们网页的流量也会随之增加。
除此之外,我们还做了一件非常棒的事――大开脑洞,把自动语音识别技术用在社交VR上,这个产品就是Social VR avatar 。如果Social VR avatar发现有一个人正在说话,那么它不仅能较准确地还原出说话人讲的内容,还能把他的动作,神情等都在虚拟任务上精确还原出来。
视频风格变换
最后,我要介绍一下Facebook另一个超级炫酷的摄像功能。
它好玩的地方是,在你录像的同时,相机可以为你的录像内容实时添加你喜欢的艺术滤镜 。我们研究这个功能的时候发现它实时添加滤镜的速度太慢了。一开始它处理一帧需要花十几秒,但如果让它在手机上实时添加滤镜的话,我们要求它一秒钟可以处理数十帧。在这里顺便提一下,作为参考,其他同类可以实时添加滤镜的应用都是在GPU服务器上跑的。这就是我们研究的时候遇到的困难。不过后来我们找到了更好的算法模型,在和FAIR实验室同仁的共同努力下,解决了这个问题。
给大家展示下面三个视频中。第一段视频是研发团队在骑自行车,你可以看到视频时加过滤镜的,并且是当时实时加上去的;第二个视频录的是美国某个城市的公交车;第三个视频是一个很有趣的小应用,用户的手移动时,手机上的小颗粒的状态也会随之有变化。
所以,我今天想和大家讲的关键点就在于,我们想设计能在生活中广泛应用的AI应用。让乡镇也能用上我们的应用是我们要实现的大目标。为了实现这个目标,我们需要让整个公司都更强大起来,我们需要专注于研发更多令人拍手称赞的平台,专注于产品的可用性,专注于建立更优秀的研究团体。
我的演讲就到这里,谢谢大家。

微信扫描二维码,关注公众号。

